前言
在上篇文章中,我们介绍了如何使用 ChaosBlade Operator 对 pod 资源进行混沌实验。从本章将继续对 Kubernetes Node 资源的混沌实验进行讲解,同时也配套了 katacode 交互式教程,读者可用通过 katacode,在浏览器上操作真实的 Kubernetes 和 ChaosBlade。
chaosblade.io 官网已经正式上线。
实验对象:Node
在 Kubernetes 中,节点(Node)是执行工作的机器,以前叫做 minion。根据你的集群环境,节点可以是一个虚拟机或者物理机器。每个节点都包含用于运行 pods 的必要服务,并由主控组件管理。节点上的服务包括 容器运行时、kubelet 和 kube-proxy。
Node 实验场景
同上篇文章,本篇默认已安装 guestbook 应用和 ChaosBlade Operator。
节点资源相关场景
节点 CPU 负载实验场景
实验目标:指定一个节点,做 CPU 负载 80% 实验。
开始实验
node_cpu_load.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: cpu-load
spec:
experiments:
- scope: node
target: cpu
action: fullload
desc: "increase node cpu load by names"
matchers:
- name: names
value:
- "docker20"
- name: cpu-percent
value:
- "80"
|
选择一个节点,修改 node_cpu_load.yaml 中的 names 值。
执行命令,开始实验:
1
| $ kubectl apply -f node_cpu_load.yaml
|
查看实验状态
执行 kubectl get blade cpu-load -o json 命令,查看实验状态。
查看实验结果
进入该 Node 节点,可以看到该节点 CPU 达到预期效果:
停止实验
执行命令:kubectl delete -f node_cpu_load.yaml
或者直接删除 blade 资源:kubectl delete blade cpu-load
节点网络相关场景
实验前,请先登录 node 节点,使用 ifconfig 命令查看网卡信息,不是所有系统默认的网卡名称都是 eth0。
节点网络延迟场景
实验目标:指定节点的本地 32436 端口添加 3000 毫秒访问延迟,延迟时间上下浮动 1000 毫秒。
开始实验
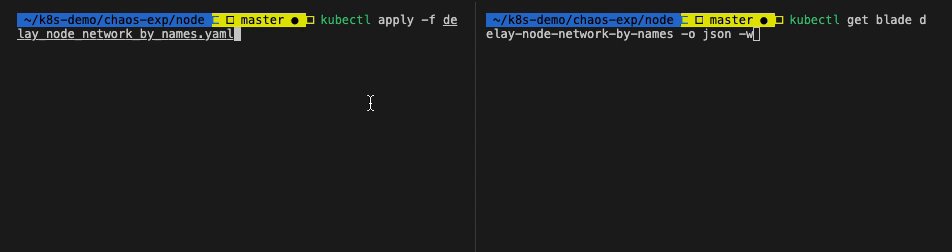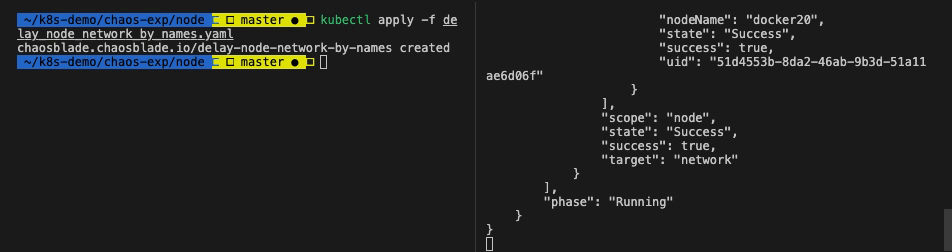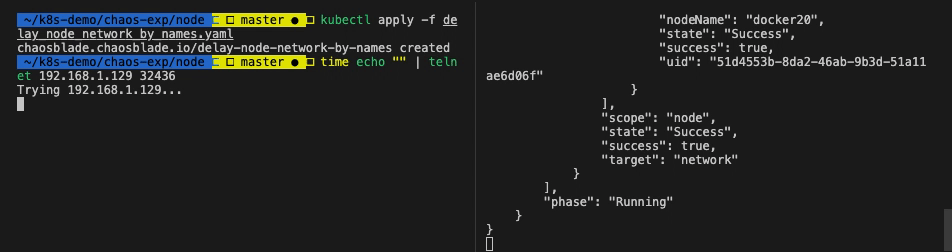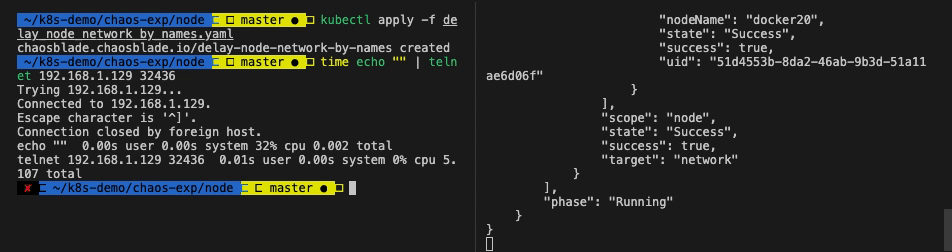
选择一个节点,修改 delay_node_network_by_names.yaml 中的 names 值。
对 docker20 节点本地端口 32436 访问丢包率 100%。
delay_node_network_by_names.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: delay-node-network-by-names
spec:
experiments:
- scope: node
target: network
action: delay
desc: "delay node network loss"
matchers:
- name: names
value: ["docker20"]
- name: interface
value: ["ens33"]
- name: local-port
value: ["32436"]
- name: time
value: ["3000"]
- name: offset
value: ["1000"]
|
执行命令,开始实验:
1
| $ kubectl apply -f delay_node_network_by_names.yaml
|
查看实验状态
执行 kubectl get blade delay-node-network-by-names -o json 命令,查看实验状态。
查看实验结果
1
2
3
4
5
6
7
8
| # 从实验节点访问 Guestbook
$ time echo "" | telnet 192.168.1.129 32436
Trying 192.168.1.129...
Connected to 192.168.1.129.
Escape character is '^]'.
Connection closed by foreign host.
echo "" 0.00s user 0.00s system 35% cpu 0.003 total
telnet 192.168.1.129 32436 0.01s user 0.00s system 0% cpu 3.248 total
|
停止实验
执行命令:kubectl delete -f delay_node_network_by_names.yaml
或者直接删除 blade 资源:kubectl delete blade delay-node-network-by-names
节点网络丢包场景
实验目标:指定节点的 32436 端口注入丢包率 100% 的故障。
开始实验
选择一个节点,修改 loss_node_network_by_names.yaml 中的 names 值。
loss_node_network_by_names.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: loss-node-network-by-names
spec:
experiments:
- scope: node
target: network
action: loss
desc: "node network loss"
matchers:
- name: names
value: ["docker20"]
- name: percent
value: ["100"]
- name: interface
value: ["ens33"]
- name: local-port
value: ["32436"]
|
执行命令,开始实验:
1
| $ kubectl apply -f loss_node_network_by_names.yaml
|
查看实验结果
执行 kubectl get blade loss-node-network-by-names -o json 命令,查看实验状态。
观测结果
该端口为 Guestbook nodeport 的端口,访问实验端口无响应,但是访问未开启实验的端口可以正常使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 获取节点 IP
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
docker20 Ready worker 3d16h v1.17.6 192.168.1.129 <none> Ubuntu 18.04.4 LTS 4.15.0-101-generic docker://19.3.11
kk Ready controlplane,etcd,worker 4d16h v1.17.6 192.168.4.210 <none> Ubuntu 18.04.4 LTS 4.15.0-101-generic docker://19.3.11
# 从实验节点访问 Guestbook - 无法访问
$ telnet 192.168.1.129 32436
Trying 192.168.1.129...
telnet: connect to address 192.168.1.129: Operation timed out
telnet: Unable to connect to remote host
# 从非实验节点访问 Guestbook - 正常访问
$ telnet 192.168.4.210 32436
Trying 192.168.4.210...
Connected to 192.168.4.210.
Escape character is '^]'.
|
同样也可以直接从浏览器访问地址,验证实验。
停止实验
执行命令:kubectl delete -f loss_node_network_by_names.yaml
或者直接删除 blade 资源:kubectl delete blade loss-node-network-by-names
节点域名访问异常场景
实验目标:本实验通过修改 Node 的 hosts,篡改域名地址映射,模拟 Pod 内域名访问异常场景。
开始实验
选择一个节点,修改 dns_node_network_by_names.yaml 中的 names 值。
dns_node_network_by_names.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: dns-node-network-by-names
spec:
experiments:
- scope: node
target: network
action: dns
desc: "dns node network by names"
matchers:
- name: names
value:
- "docker20"
- name: domain
value: ["www.baidu.com"]
- name: ip
value: ["10.0.0.1"]
|
执行命令,开始实验:
1
| $ kubectl apply -f dns_node_network_by_names.yaml
|
查看实验状态
执行 kubectl get blade dns-node-network-by-names -o json 命令,查看实验状态。
查看实验结果
1
2
3
4
5
| # 进入实验 node
$ ssh kk@192.168.1.129
# Ping www.baidu.com
$ ping www.baidu.com
# 无响应
|
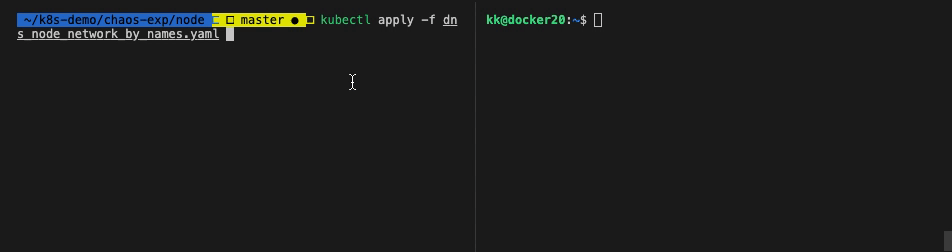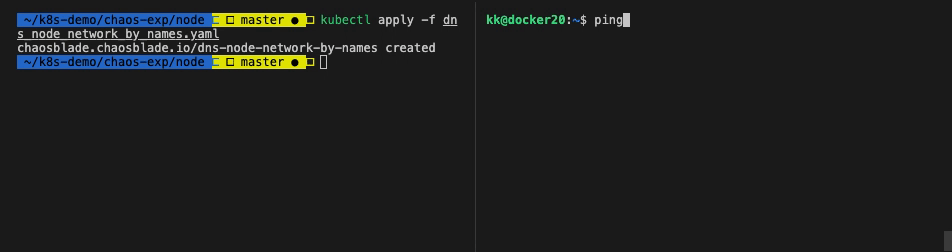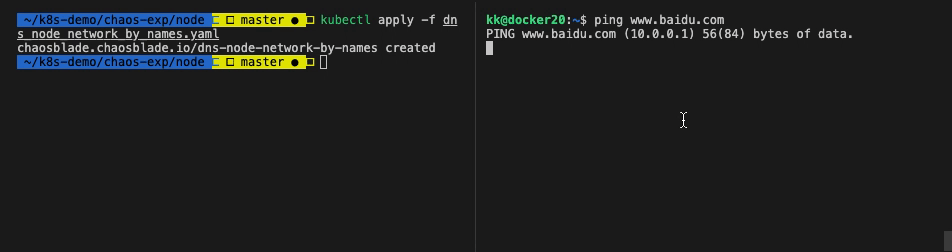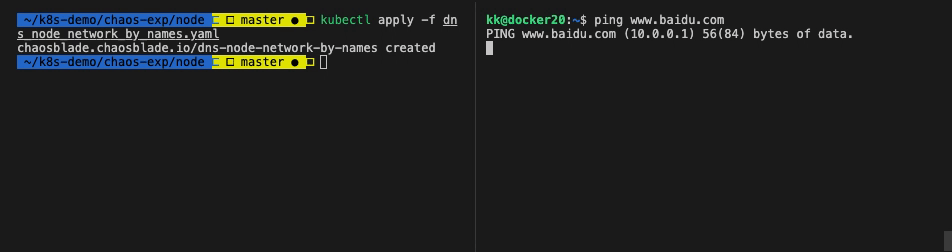
可以看到 Node 的 /etc/hosts 文件被修改,模拟了 dns 解析异常的场景。
停止实验
执行命令:kubectl delete -f dns_node_network_by_names.yaml
或者直接删除 blade 资源:kubectl delete blade dns-node-network-by-names
节点磁盘相关场景
kubernetes 节点磁盘场景。
节点磁盘填充场景
实验目标:指定节点磁盘占用 80%
开始实验
选择一个节点,修改 fill_node_disk_by_names.yaml 中的 names 值。
fill_node_disk_by_names.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: fill-node-disk-by-names
spec:
experiments:
- scope: node
target: disk
action: fill
desc: "node disk fill"
matchers:
- name: names
value: ["docker20"]
- name: percent
value: ["80"]
|
执行命令,开始实验:
1
| $ kubectl apply -f fill_node_disk_by_names.yaml
|
查看实验状态
执行 kubectl get blade fill-node-disk-by-names -o json 命令,查看实验状态。
查看实验结果
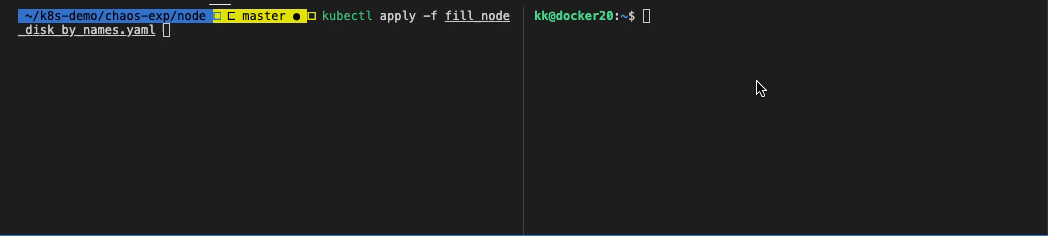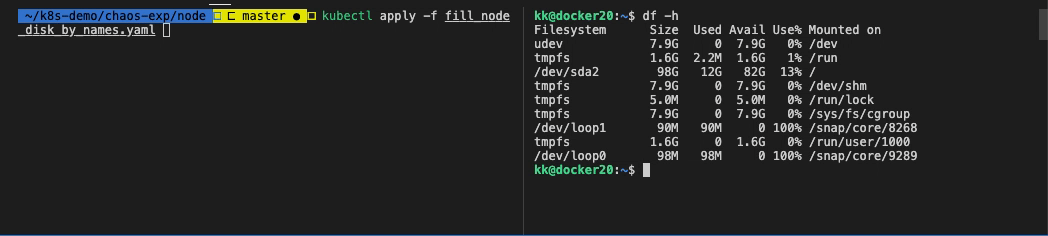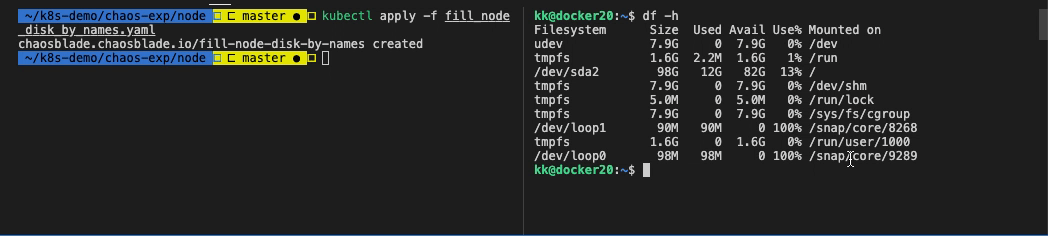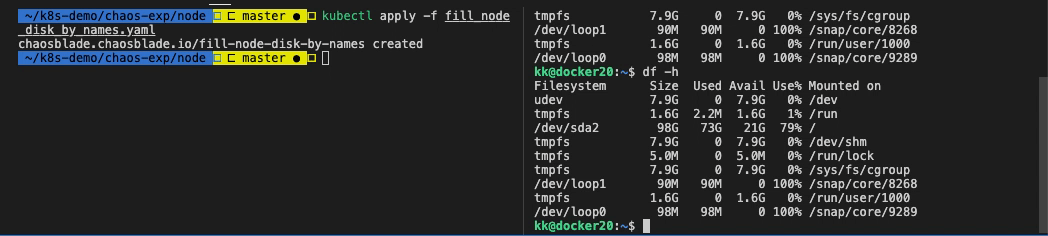
可以看到磁盘占用 80%。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 进入实验 node
$ ssh kk@192.168.1.129
# 查看磁盘使用率
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 7.9G 0 7.9G 0% /dev
tmpfs 1.6G 2.2M 1.6G 1% /run
/dev/sda2 98G 73G 20G 79% /
tmpfs 7.9G 0 7.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 7.9G 0 7.9G 0% /sys/fs/cgroup
/dev/loop1 90M 90M 0 100% /snap/core/8268
tmpfs 1.6G 0 1.6G 0% /run/user/1000
/dev/loop0 98M 98M 0 100% /snap/core/9289
|
停止实验
执行命令:kubectl delete -f fill_node_disk_by_names.yaml
或者直接删除 blade 资源:kubectl delete blade fill-node-disk-by-names
节点进程相关场景
kubernetes 节点进程相关场景。
杀节点上指定进程
实验目标:此实验会删除指定节点上的 redis-server 进程。
开始实验
选择一个节点,修改 kill_node_process_by_names.yaml 中的 names 值。
kill_node_process_by_names.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: kill-node-process-by-names
spec:
experiments:
- scope: node
target: process
action: kill
desc: "kill node process by names"
matchers:
- name: names
value: ["docker20"]
- name: process
value: ["redis-server"]
|
执行命令,开始实验:
1
| $ kubectl apply -f kill_node_process_by_names.yaml
|
查看实验状态
执行 kubectl get blade kill-node-process-by-names -o json 命令,查看实验状态。
查看实验结果
1
2
3
4
5
6
7
8
| # 进入实验 node
$ ssh kk@192.168.1.129
# 查看 redis-server 进程号
$ ps -ef | grep redis-server
root 31327 31326 0 06:15 ? 00:00:00 redis-server *:6379
# 可以看到进程号发生了变化
$ ps -ef | grep redis-server
root 2873 2872 0 06:23 ? 00:00:00 redis-server *:6379
|
redis-server 的进程号发生改变,说明被杀掉后,又被重新拉起。
停止实验
执行命令:kubectl delete -f kill_node_process_by_names.yaml
或者直接删除 blade 资源:kubectl delete blade kill-node-process-by-names
挂起节点上指定进程
实验目标:此实验会挂起指定节点上的 redis-server 进程。
开始实验
选择一个节点,修改 stop_node_process_by_names.yaml 中的 names 值。
stop_node_process_by_names.yaml 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| apiVersion: chaosblade.io/v1alpha1
kind: ChaosBlade
metadata:
name: stop-node-process-by-names
spec:
experiments:
- scope: node
target: process
action: stop
desc: "kill node process by names"
matchers:
- name: names
value: ["docker20"]
- name: process
value: ["redis-server"]
|
执行命令,开始实验:
1
| $ kubectl apply -f stop_node_process_by_names.yaml
|
查看实验状态
执行 kubectl get blade stop-node-process-by-names -o json 命令,查看实验状态。
查看实验结果
1
2
3
4
5
| # 进入实验 node
$ ssh kk@192.168.1.129
# 查看 redis-server 进程号
$ ps aux| grep redis-server
root 5632 0.0 0.0 41520 4168 ? Tl 06:28 0:06 redis-server *:6379
|
可以看到 redis-server 此刻进程处于暂停状态了(T)。
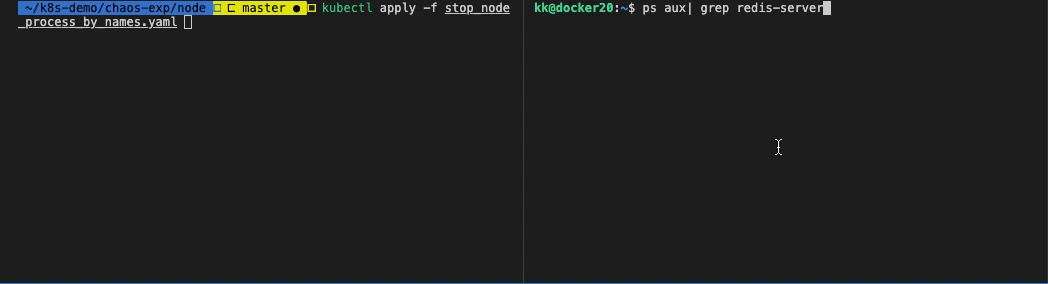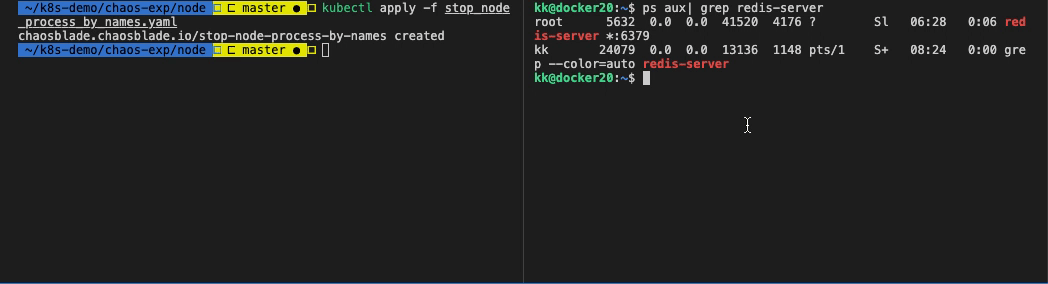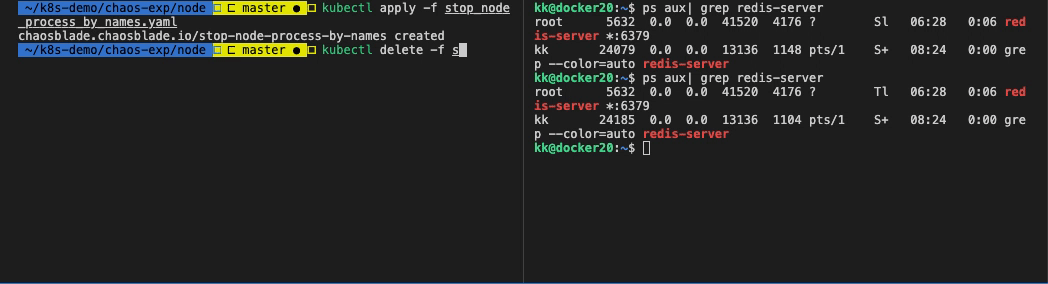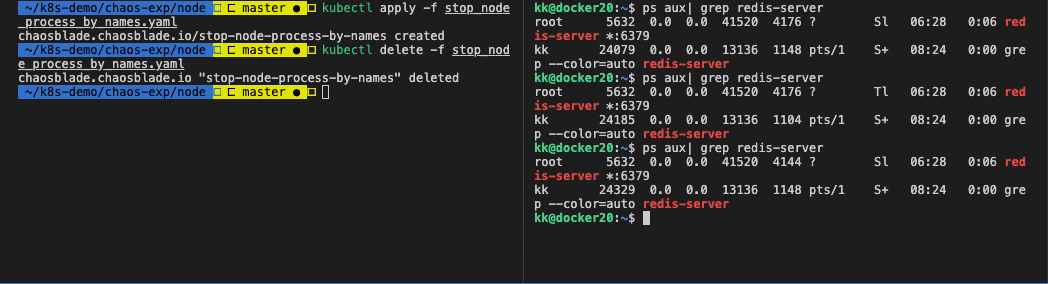
停止实验
执行命令:kubectl delete -f stop_node_process_by_names.yaml
或者直接删除 blade 资源:kubectl delete blade stop-node-process-by-names
结语
本篇我们使用 ChaosBlade Operator 对 Kubernetes Node 资源进行混沌工程实验,可以看到对于 Node 节点,ChaosBlade 依旧有简单的配置及操作来完成复杂的实验,可以通过自由组合,实现各种 Node 节点级别的复杂故障,验证 Kubernetes 集群的稳定性及可用性。同时当真正的故障来临时,由于早已模拟了各种故障情况,可以快速定位故障源,做到处变不惊,轻松处理故障。